leveldb(三) 内存序
在(二)中讲了skiplist,其实跳过了颇为重要的一部分
为了保证skiplist的线程安全
skiplist中对两个变量使用了原子变量
1 | std::atomic<int> max_height_; // Node的最大高度 |
涉及这两个变量的存取涉及到了三种内存序
- std::memory_order_release
- std::memory_order_relaxed
- std::memory_order_acquire
下面讲一下内存序
内存序
三级cache
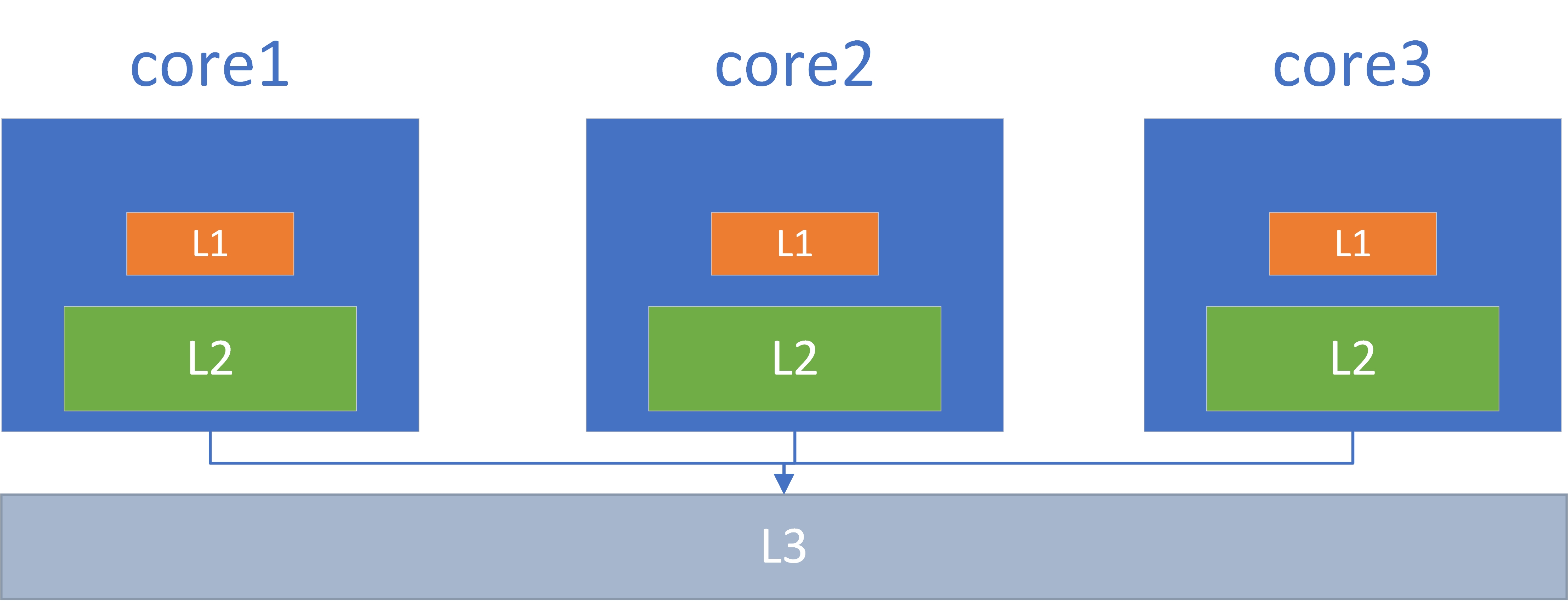
正是这样的SMP架构(共享多处理器),cache存在本地(L1/L2)的和共享(L3),因而存在一致性的问题
即core1读到数据A后,进行修改,没有及时写回共享cache(L3),此时倘若core2读数据A,这时候读到的就是旧值,此时core1的写和core2的读就没有完成同步
内存屏障
C++11中的内存序
c++11中引入了六种内存序
- relaxed
- acquire
- release
- consume
- acq_rel
- seq_cst
六种内存序实际上实现了三种内存模型
- relaxed(要求最低,性能最好)
- acquire release
- sequential consistent
他们保证了个啥呢
(以下感谢如何理解 C++11 的六种 memory order? - 知乎 (zhihu.com),同时参考了std::memory_order - cppreference.com)
- relaxed order
- 只保证了单个线程内的原子操作是顺序的
- 线程间呢?你想咋搞就咋搞
- release–acquire
- 类似于mutex的lock和unlock操作
- 线程A原子性的存入X (release),线程B原子性的读X(acquire),(其实就是将新值从local cache中更新到了shared cache,而且读的线程也从shared cache中获取新值嘛)
- 同时带来一个副作用——线程A中存入X之前的操作,在线程B执行读取X之后都能看见(因为线程A这时的local cache已经更新了,而且线程B的cache也从shared cache中更新)
- release–consume
- release–acquire这个副作用太强了,我想避免这个开销怎么办?
- release–consume中的副作用变成了依赖读和依赖写,就是线程A中,存入X之前的依赖X的写操作,在线程B中读取X后,依赖X的读操作都能看到
- seq_cst
下面结合LevelDB中的一个例子
1 | Node* Next(int n) { |
Next函数返回在高度n下的下一个node节点
SetNext函数设置在高度n下的下一个节点为x
这里通过release-acquire,保证了三个东西
- 1的运行一定在2之前,即通过Next(n)读到的node一定是已经初始化了的
- 3的运行一定在4之前,保证SetNext(n)设置的node一定是已经初始化了的
- 同时在release的store之前的操作,在acquire的load之前都可见(就是上面说的synchronize with语义
同时,由于性能的优化,还实现了no barrier版本的
1 | Node* NoBarrier_Next(int n) { |
而且实际上insert调用的就是无屏障版本的(显然是出于性能的考虑)
1 | template <typename Key, class Comparator> |
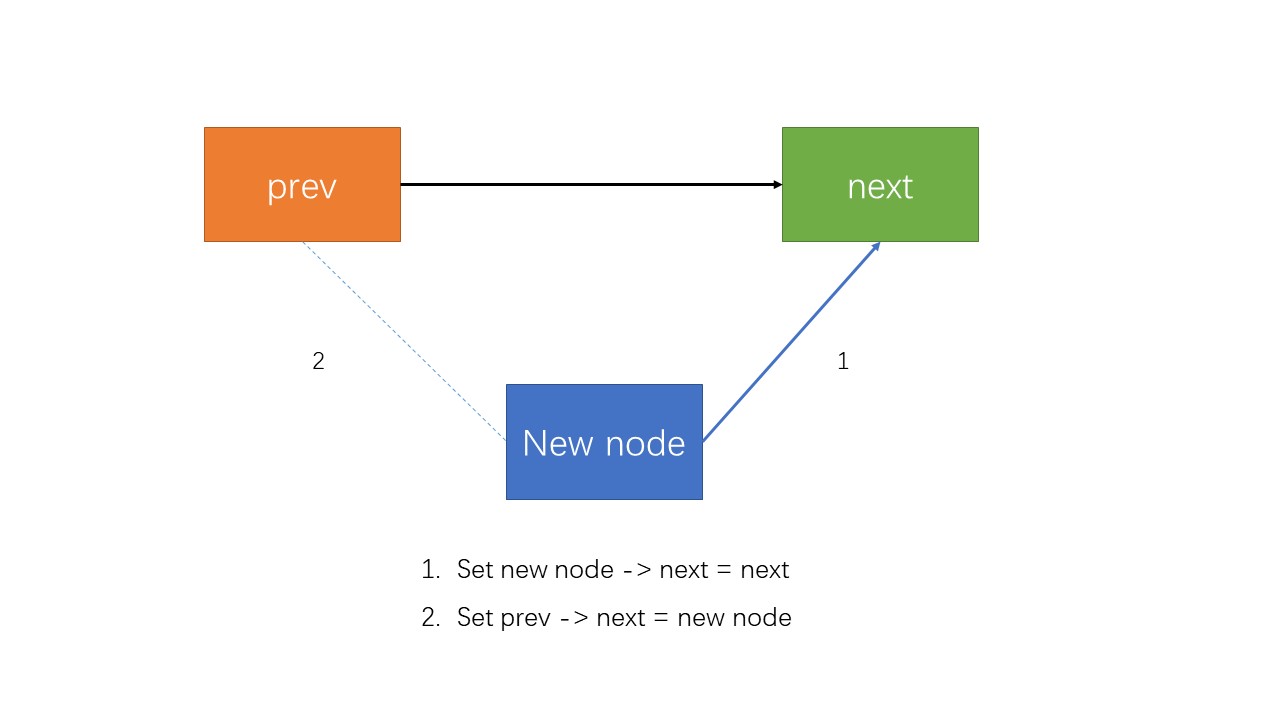
其中作者也解释了为什么此处可以使用无屏障版本的(无需同步)
实际上insert可以分为两步
- 将新节点的next设为当前的next
- 将prev的next设为当前节点
倘若发生了1,还没同步,这时候其他并发的线程读到的next还是next,不影响下一步操作