leveldb(一) 初识
LevelDB是一个基于Log Structured Merged Tree(LSM tree)的KV数据库。什么是LSM tree?跟其他kv数据库有什么区别?
下面从最简单的三个什么开始,为什么,为什么,怎么做?
为什么?
磁盘的顺序写速度远快于随机写的速度(减少了磁盘寻道的时间)。
而对于写多读少的场景,对于写的优化更为重要。
想象目前需要update a = 1。写入a的值,需要找到存a的表存在哪个页中,再通过偏移找到a的位置,修改那个地址的值为1,这个过程随机写跑不掉。怎么优化呢?想到WAL中log的写法,不直接写入a,而是写入修改a这条命令。所以才有log-structured这个名字。
当然了,优化了写,也放大了读。。。这是后话
做什么?
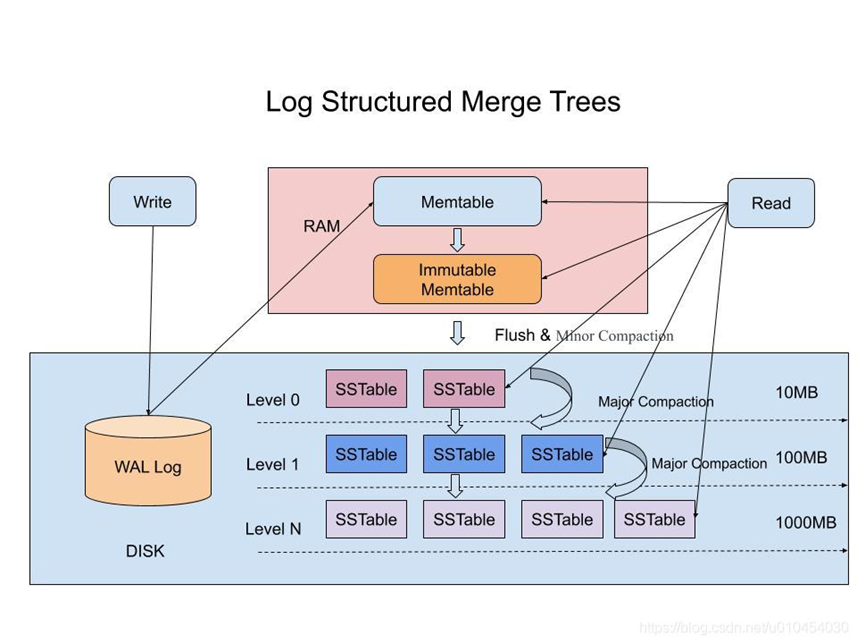
LSM tree的基本结构如下
- Meltable
- 作为数据存入的第一个池子,所以里面放的一定是数据最新的更新版本
- 按key值有序(方便用logn的时间进行二分查找)
- 存在易失性内存中
- Immutable meltable
- 放数据的第二个池子,但只接受memtable流出的数据(顾名思义,immutable)
- 跟meltable类似,同样按key值有序
- 同样存在易失性内存中
- 为什么还要加一个immutable的memtable?
- 因为memtable需要flush到磁盘上,跟sstable进行合并,这时候对memtable的其他写操作会被阻塞,会很影响写性能
- 在磁盘上持久化存储的各级sstable
- 存在非易失性存储中,数据得以持久化
- sstable大小固定,但各级sstable的数量依次递增
- 同样按key值有序
怎么做?
数据写进去发生了什么?
- 先写入memtable,memtable满了,再通过compaction的方式,与immutable memtable合并,形成新的immutable memtable,再如此类推,所以compaction的操作是需要在后台不断进行的(性能影响点之一)
需要读数据时,又发生了什么?
- 先找sstable,如果有相同的看时间戳,取最晚的(因为是log-structured结构的数据,取过时的可能会翻车,从sstable找起同理),之后再找immutable stable,如此类推
- 显然读性能放大了至少N倍,部分冷数据和不存在的数据要到最低一层的ss才能找到,所以引入了bloom filter的优化
- 可以把Bloom filter想象成一个巨大的位图,将每个数据都做与运算,假如数据哈希到的位置上,哈希表有1位为0,代表这个数据肯定不在,只能优化对于不存在的数据的查询
后续想看的模块
- 基本数据结构的实现
- SSTable使用的数据结构跳表的实现
- 日志的实现
- 布隆过滤器bloom filter的实现
- 日志compaction的实现
- levelDB对外暴露的接口和封装